Umbraco media search with Azure AI Vision

I’ve been writing a lot about Umbraco Search lately. With good reason; it really is a game changer for all things search within the Umbraco space.
When I glanced over my latest posts, I realized they were all about searching for documents… which makes sense, because that is the predominant use case for Umbraco Search.
But Umbraco Search also allows for searching media and members out of the box, so this will be a post about building search for media 🖼️
But - with a twist
Searching for media (and members, for that matter) works exactly the same as searching for documents with Umbraco Search. And exactly the same extension points are available too.
In other words, this would be a really boring post without a plot twist. Enter AI 🤖
In this post, I’ll show you how you can combine an external image recognition service (in this case, Azure AI Vision) and Umbraco Search to automate image content search, based on both tagging and textual description.
You can find the complete solution in this GitHub repo, if you want to experiment with it. The Umbraco admin credentials are:
- Username: admin@localhost
- Password: SuperSecret123
You’ll also need to update appsettings.json with the endpoint and API key for your Azure AI Vision instance - look for the AzureVisionConfiguration section.
So how does this all work?
Umbraco Search automatically indexes all media properties when they are saved, just like documents. So, the goal here is to enrich images with searchable properties after upload 🔎
When an editor uploads an image, it’ll be sent off to the external image recognition service for processing. Upon completion, the resulting image description and tags are stored on the image, to be used for image content search.
The image processing is performed asynchronously on a background thread, so it does not cause delays for the editors ⌛
This all sounds terribly complicated, but in fact, all the hard parts have already been built - it’s only a matter of piecing things together:
- Umbraco allows custom code to run at certain system events (such as media editing) via notification handlers.
- Umbraco has a built-in support for queueing background tasks on demand.
- Umbraco Search automatically re-indexes media when they’re saved.
- Azure AI Vision has a NuGet package to ease the integration work.
So, a notification handler it is!
The notification handler
Specifically, it’s a handler for the MediaSavedNotification, which is triggered whenever a media item is saved.
The notification handler:
- Verifies that the saved media item is indeed an image and not another kind of file (or even a folder, which is technically also a media item).
- Checks if the binary image content was changed, thus requiring image analysis to update tags and description.
- Queues the image analysis as a background task.
- Updates the tags and description properties of the media item with the image analysis result.
I have added a tags and a description property to the “Image” media type, so the notification handler has a place to store the image analysis result
It looks something like this:
public class ImageAnalysisNotificationHandler : INotificationHandler<MediaSavedNotification>
{
private readonly IBackgroundTaskQueue _backgroundTaskQueue;
private readonly IMediaService _mediaService;
private readonly IJsonSerializer _jsonSerializer;
// (additional service dependencies and constructor removed for brevity)
public void Handle(MediaSavedNotification notification)
{
foreach (var media in notification.SavedEntities)
{
// only analyze "Image" media types.
if (media.ContentType.Alias is not Constants.Conventions.MediaTypes.Image)
{
continue;
}
// only trigger the analysis if the "umbracoBytes" property changed (the binary image content was changed).
if (media.WasPropertyDirty(Constants.Conventions.Media.Bytes) is false)
{
continue;
}
// queue the image analysis in a background task.
var mediaKey = media.Key;
_backgroundTaskQueue.QueueBackgroundWorkItem(
async cancellationToken => await BackgroundMediaProcessing(mediaKey, cancellationToken)
);
}
}
private async Task BackgroundMediaProcessing(Guid mediaKey, CancellationToken cancellationToken)
{
// get the media item targeted for processing.
var media = _mediaService.GetById(mediaKey);
if (media is null)
{
return;
}
// perform image analysis
var result = await PerformImageAnalysis(media, cancellationToken);
if (result.HasValue is false)
{
return;
}
// update the "tags" and "description" values of the media item.
media.SetValue("tags", _jsonSerializer.Serialize(result.Value.Tags));
media.SetValue("description", result.Value.Description);
// save the changes back to the media item. this automatically triggers a re-index for Umbraco Search.
_mediaService.Save(media);
}
private async Task<(string[] Tags, string? Description)?> PerformImageAnalysis(IMedia media, CancellationToken cancellationToken)
{
// (image analysis implementation removed for brevity)
}
}
I have omitted a few bits and pieces in the code sample for brevity. You’ll find the complete code in the GitHub repo.
The image search
As I mentioned in the beginning of this post, there is no principal difference between media and document search with Umbraco Search.
The only practical difference is to target the correct index alias. The rest is a matter of adhering to the media schema (the media type) rather than the document schema when performing search.
To prove that point, I have cloned the document search demo site from one of my previous posts, and tweaked the implementation of the search API controller to search for media rather than documents.
For comparison, here’s the original API controller for document search.
Apart from the controller name change, these are the changes made:
- The fields that power filtering and faceting have changed to match the media type schema.
- The search index used for querying is the default index for media, rather than the default index for published documents.
- The response model for each media search result item is a custom class, rather than the Delivery API output format.
As you can probably tell, these are really minor changes, because at the end of the day, it’s all happening within the Umbraco Search space.
Here’s how the final result renders in the frontend:
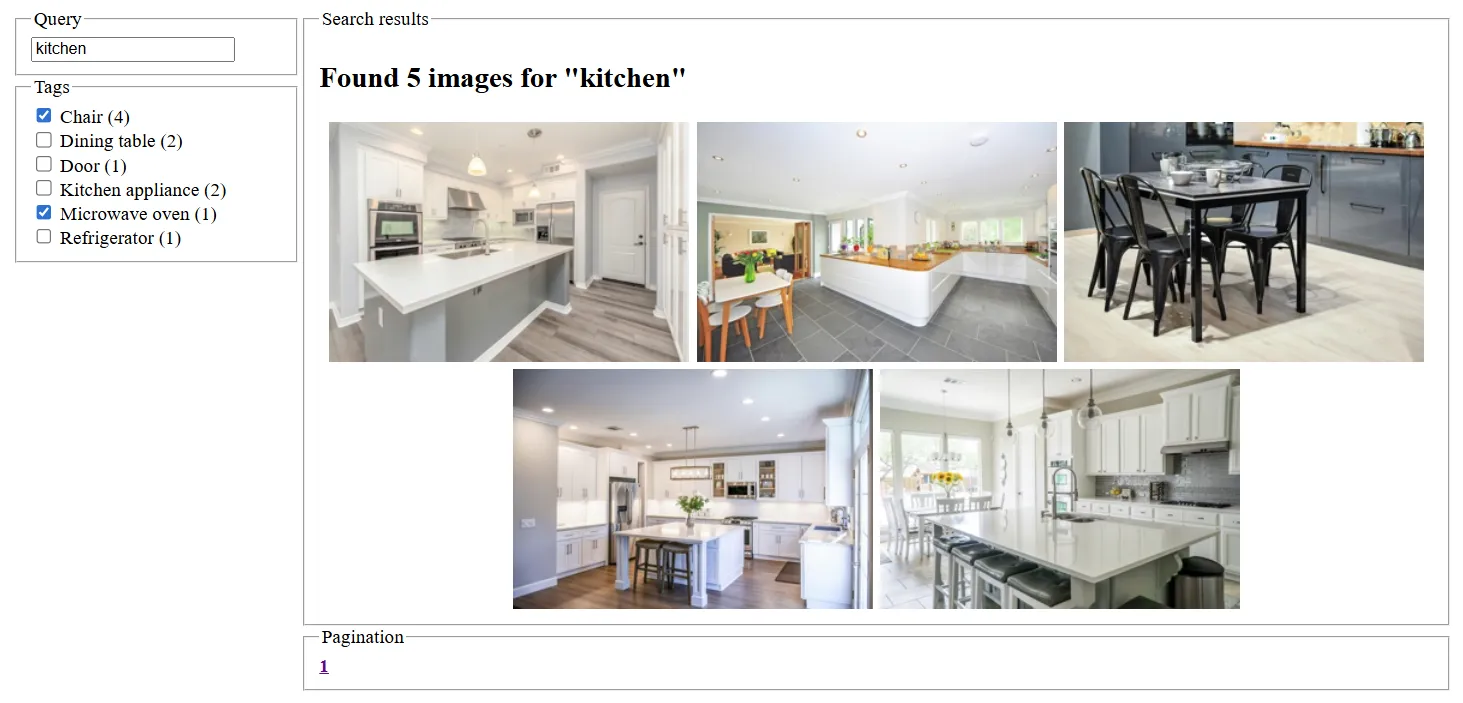
Ain’t it pretty 🫣
At the end of the day, it’s all integration
Umbraco has always been excellent at integrating with other systems. If anything, this post is actually more about integration than it is about search.
It’s really just icing on the cake that Umbraco Search automatically picks up the data from the integration, and makes them available for filtering and querying 👏
As always,
Happy hacking 💜